One of the leading technical challenges of our generation is edge computing: how to take compute-intensive AI tasks and perform them on resource-constrained embedded devices. In this pursuit, the hardware and software are fundamentally at odds with each other as designers try to simultaneously balance low power, low cost, and high performance.
SiMa.ai, a machine learning hardware startup, is now trying to address this challenge by designing “software-first” hardware to enable unprecedented edge AI performance. This week, SiMa.ai released their new MLSoC Platform, an ML-centric SoC that aims to make edge AI more intuitive and flexible than ever before.
In this article, we’ll discuss the current state of edge AI and how SiMa.ai’s new platform hopes to address some of its shortcomings.
Current State of Edge AI
When it comes to taking AI to the edge, also known as TinyML, the process is often very hardware-centric.
Generally, the challenge with edge AI is that devices are very resource-constrained, having a limited amount of RAM, processing power, and battery life. Because of this, the TinyML design process often revolves around tailor-fitting the machine learning models to the mostly predetermined hardware capabilities of the device.
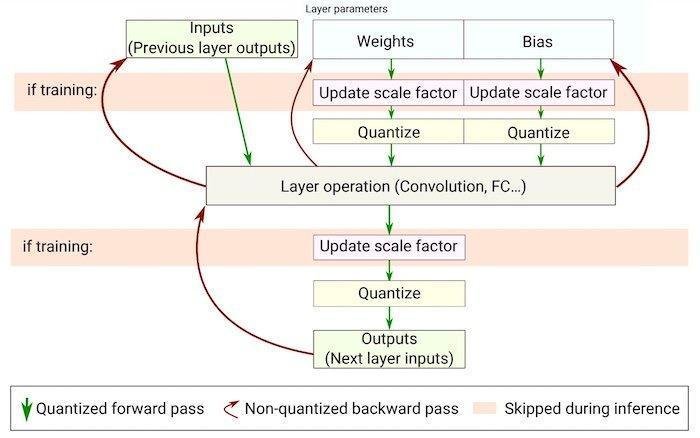
Flow chart of quantization-aware training. Image used courtesy of Novac et al
To do this, the software flow consists of taking a given machine learning model, training it on the desired dataset, and then scaling it down to fit the constraints of the edge device. This model scaling is often done through the process of quantization, which is the process of decreasing the precision of model weights and parameters such that they consume less memory.
In this way, TinyML engineers can take a large machine learning model, which was designed for deployment on a more powerful device, and scale it down to fit the edge device.
The issue with this workflow, as SiMa.ai sees it, is that the models aren’t actually designed for the edge, rather they’re adapted for it. This is limiting in terms of performance and flexibility, as the models are never truly optimized for the hardware and vice versa.
SiMa’s New SoC Solution
To address this issue, SiMa.ai has recently released their MLSoC Platform, a “software-first” edge AI SoC.
Built on a 16nm process, the MLSoC Platform is a heterogeneous computing system-on-chip (SoC) that integrates a number of dedicated hardware blocks for AI acceleration. Amongst this hardware, blocks include SiMa.ai’s proprietary machine learning accelerator (MLA). The company says it offers 50 TOPS for neural network computation at 10 TOPS/W.
The SoC’s application processing unit (APU) consists of a cluster of four, 1.15 GHz Arm Cortex-A65 dual threaded processors. There is also a video encoder and decoder block and a computer vision unit (CVU), which consists of a four-core Synopsys ARC EV74 embedded vision processor. These blocks are supported by 4 MB of on-chip memory as well as interfaces for 32-bit LPDDR4 DRAM. More information can be found in the MLSoC product brief.
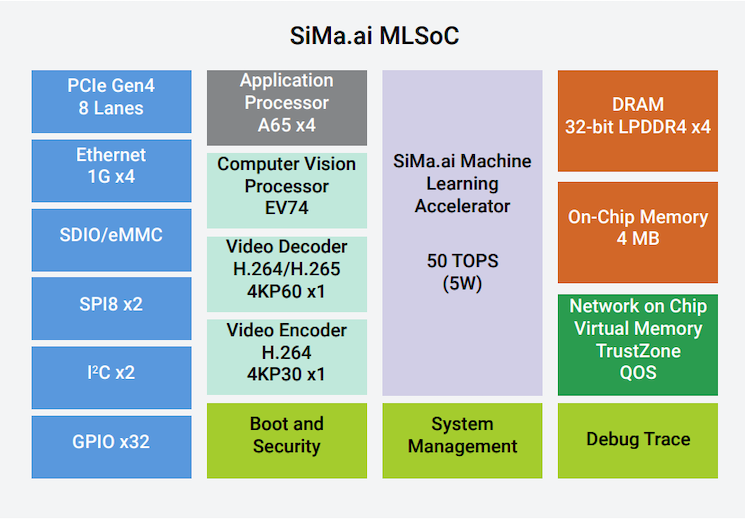
Block diagram of MLSoC. Image used courtesy of SiMa.ai
Beyond the hardware, however, SiMa.ai claims its MLSoC platform is unique in that it was co-designed with its ML software toolchain. Specifically, the company claims that its approach includes carefully defined intermediate representations plus novel compiler optimization techniques to enable support for a wide range of frameworks and networks.
These frameworks include favorites such as TensorFlow, PyTorch, and ONNX, while also claiming support for over 120+ networks. The idea is that by using the MLSoC software toolchain, engineers can develop ML models that are meant specifically for the MLSoC SoC, allowing for greater design flexibility, efficiency, and performance.
A Reimagined Approach to TinyML?
Overall, the company claims that their MLSoC platform, which is now shipping to customers, can deliver a 10x performance/power solution in computer vision as compared to competitors in class. To support this, they claim a best-in-class DNN inference efficiency of 500 FPS/W on ResNet-50 v1 with a batch size of 1.
With their unique approach to software/hardware compatibility, SiMa.ai hopes to re-imagine the industry’s approach to TinyML, and, with it, unlock unprecedented performance and efficiency.